

Table of Links
-
4.1 Multi-hop Reasoning Performance
4.2 Reasoning with Distractors
A. Dataset
B. In-context Reasoning with Distractors
E. Experiments with Large Language Models
4.5 Memorizing Knowledge

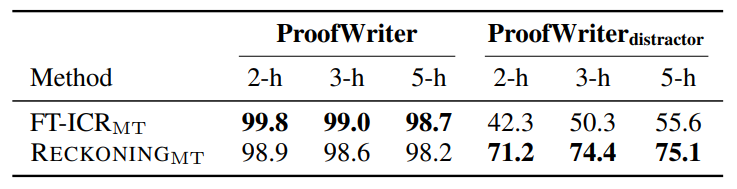
The results show that RECKONINGMT can successfully (average exact match score of 99.3%) recover the relevant facts from its model parameters when the context does not include any distractors. Note that this is comparable to the FT-ICR baseline, for which the task is much easier as it can directly attend to and copy the facts from input, while RECKONINGMT no longer has direct access to them. When the context includes distractors, both RECKONING and FT-ICR struggle to identify and reproduce only the relevant facts. However, the performance for FT-ICR (average 49.4%) drops far below that of RECKONING (73.6%), demonstrating that RECKONING is much better at disentangling the relevant knowledge from the distractors.
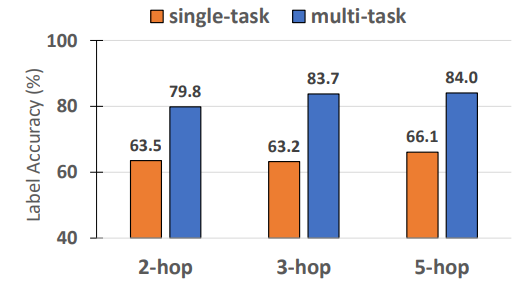
Finally, we show that RECKONING with a multi-task objective is also more robust to distractors as it trains the model to reproduce only the facts that would be relevant to a particular question we ask in the outer loop. As in Section 4.2, we use the ProofWriter dataset and, for each question, add all the distractors to the context. We train the model using the multi-task objective and report the label accuracy. While in Table 1, we originally saw a ∼ 1% improvement from training with a multi-task objective on ProofWriter with no distractors, we see a much more significant performance gap in Figure 6 (∼ 18.2%) when distractors are available. We also note that the performance of the single-task model is essentially random (see the Random-Facts baseline from Table 1). By learning how to memorize knowledge in the inner loop to recall relevant facts in the outer loop, the model also learns how to encode facts more robustly over them.
Authors:
(1) Zeming Chen, EPFL ([email protected]);
(2) Gail Weiss, EPFL ([email protected]);
(3) Eric Mitchell, Stanford University ([email protected])';
(4) Asli Celikyilmaz, Meta AI Research ([email protected]);
(5) Antoine Bosselut, EPFL ([email protected]).
This paper is
[3] We perform this experiment in a limited setting and do not handle the case where hidden states could be cached for the forward pass of in-context reasoning, likely speeding up multi-question inference [12].
[4] This is done by prompting the model with the question and comparing its output (after its answer to the question) to the concatenation of all facts. The model is able to produce these facts in the expected order due to an implementation detail: they are numbered and labeled when given to the inner loop.